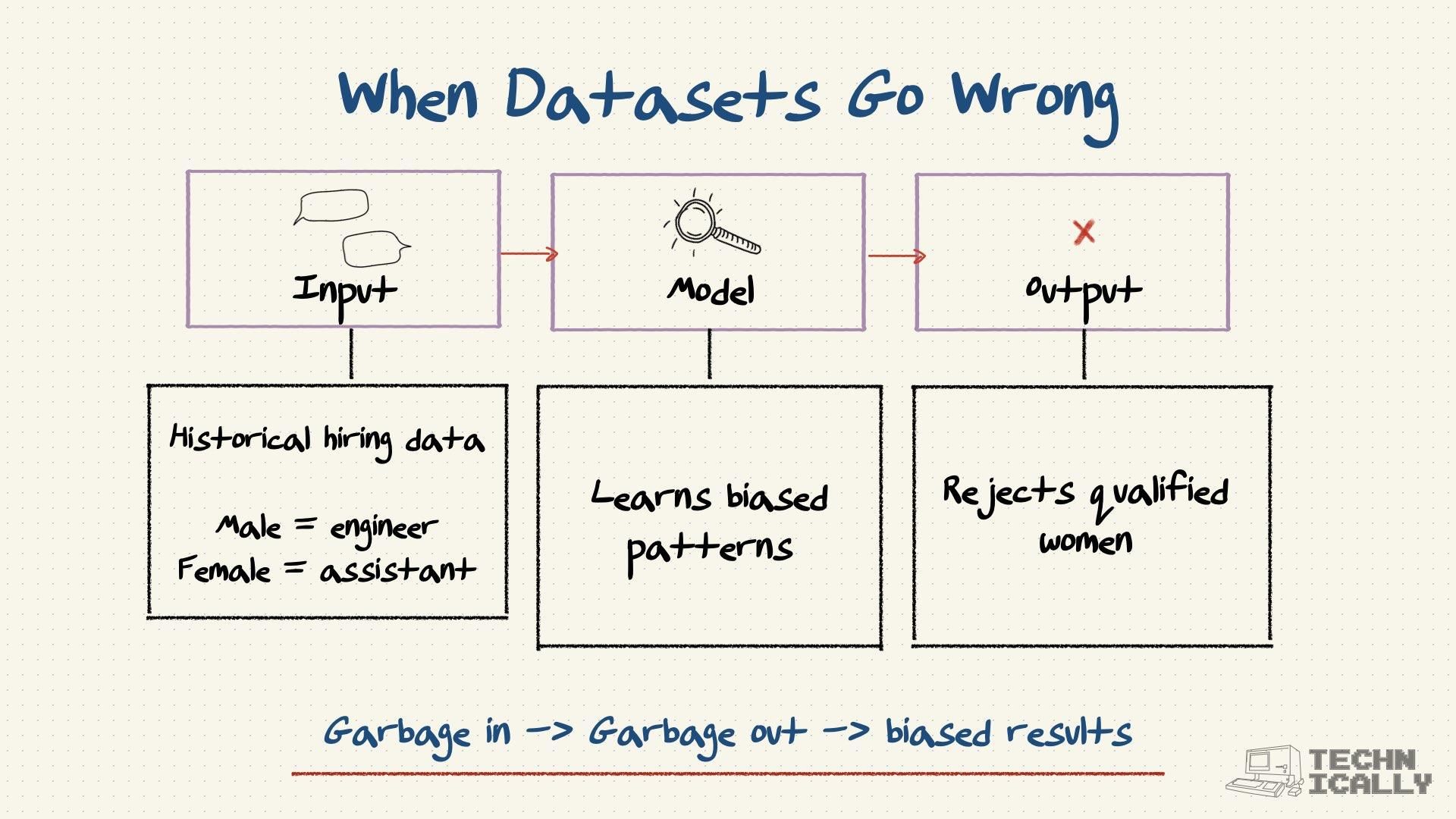
Other FAQs on AI training datasets#
Can you use the same dataset for different models?#
Absolutely, and it happens all the time. Benchmark datasets like ImageNet are used to compare different models fairly - kind of like having a standardized test that all students take so you can see which teaching methods work best. It's also way more efficient than everyone creating their own datasets from scratch.
What happens if your dataset is too small?#
Your model "overfits" - basically, it memorizes the specific examples instead of learning general patterns. It's like a student who memorizes practice tests word-for-word but completely bombs when they see new questions. The model will perform amazingly on your training data and terribly on anything else.
Can you combine different types of data?#
Yep, and multimodal datasets are getting really popular. For example, pairing images with captions teaches models to understand both visual and textual information. This is how AI can look at a photo and write a description of what's happening - pretty cool stuff.
How do you know if your dataset is good enough?#
You test the hell out of it. Train your model, then throw real-world examples at it and see how it performs. If it's struggling, you might need more data, better labels, or more diverse examples. It's an iterative process - kind of like cooking, where you keep tasting and adjusting until it's right.
Can AI help create datasets?#
More and more, yes. AI can help with data collection, pre-labeling (which humans then double-check), and even generating synthetic data. But you still need human oversight for quality control and bias detection. AI helping create datasets to train other AI - it's turtles all the way down.
What's synthetic data?#
Artificially generated examples that look like real data but are created by computers. For example, AI-generated faces for training facial recognition systems. It's cheaper than collecting real data and can help with privacy issues, but you have to be careful that your synthetic data actually captures the messiness and complexity of real-world scenarios.