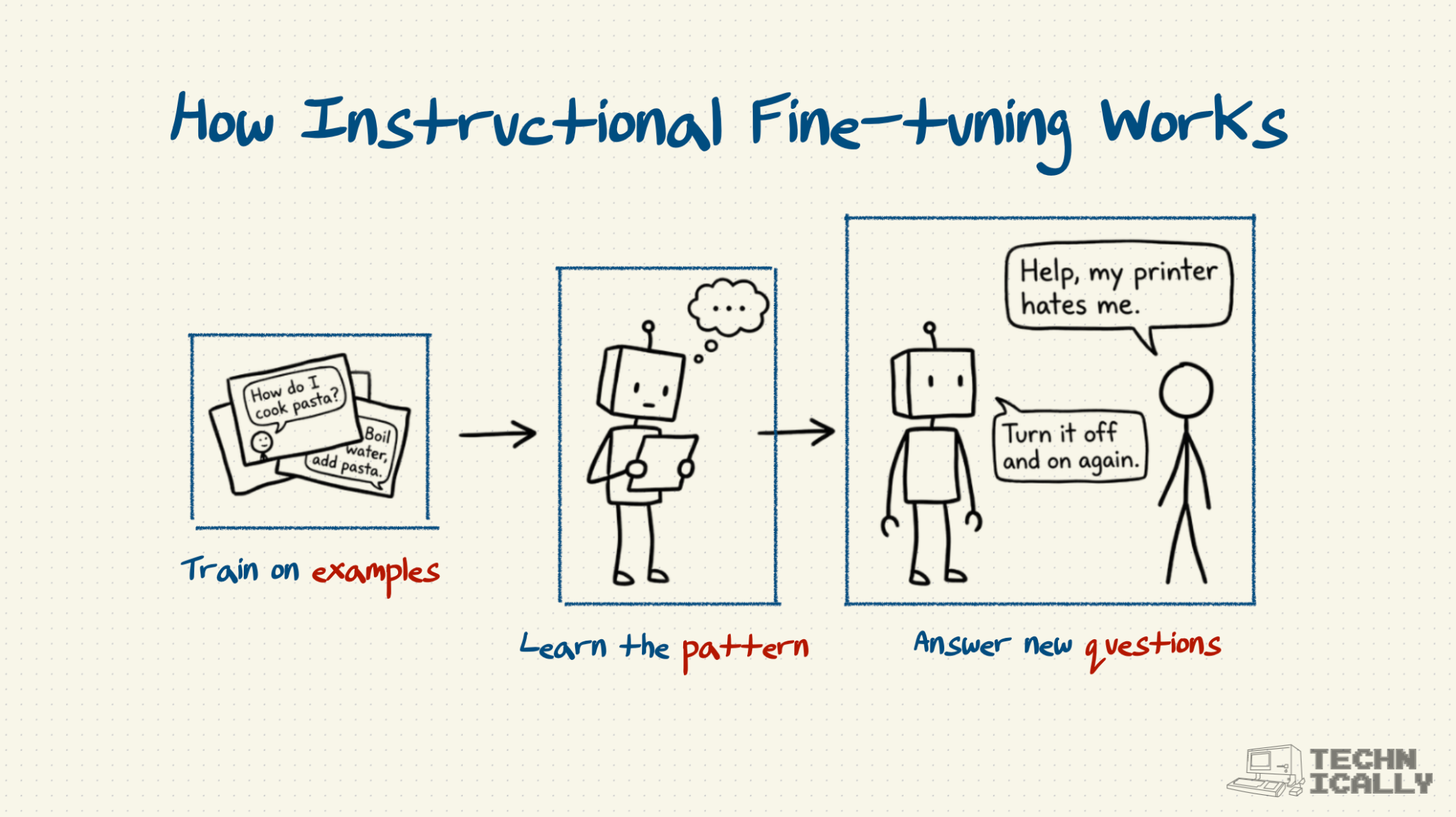
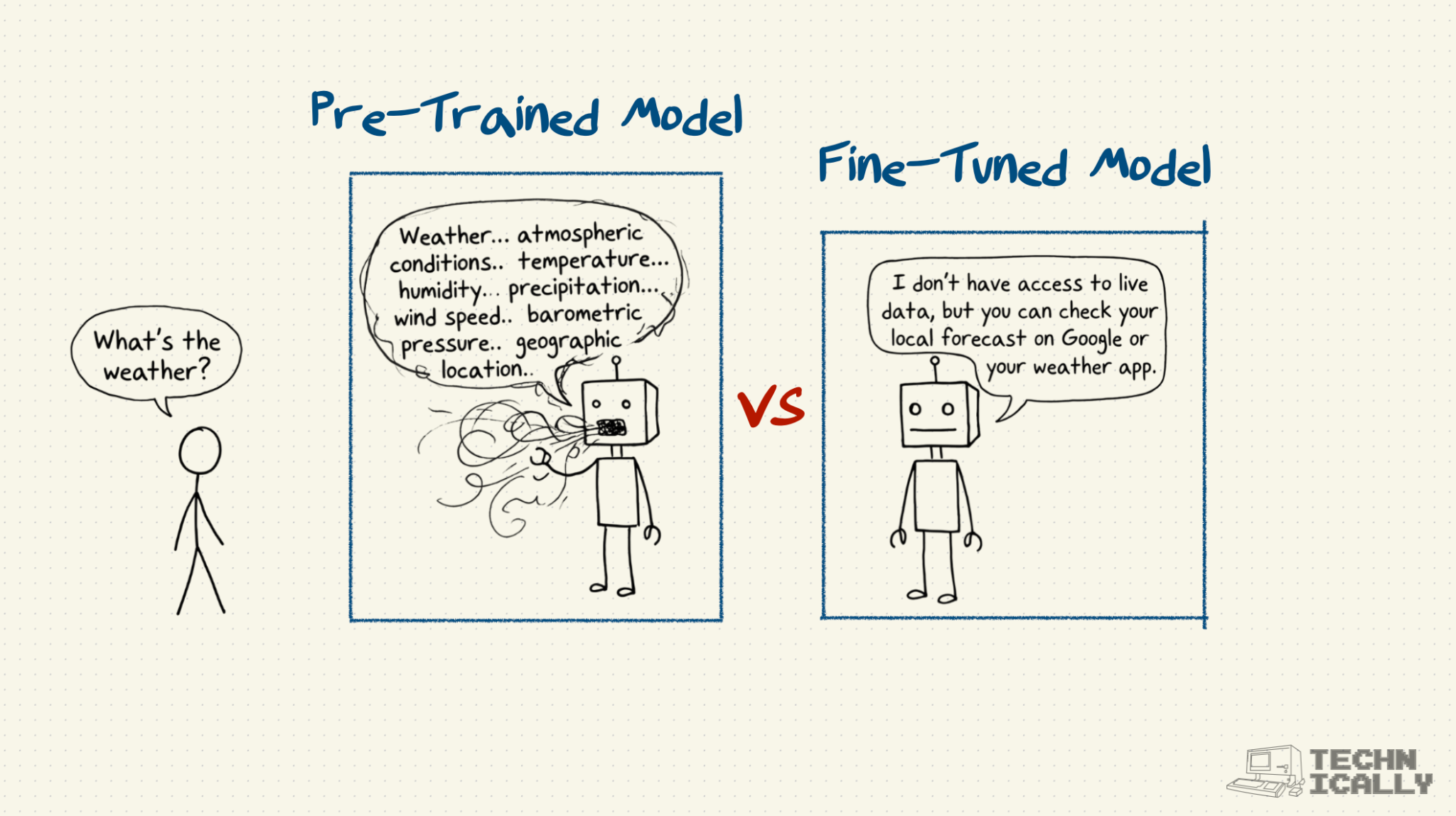
Instructional fine-tuning is how you turn a pre-trained AI model – knowledgeable, but useless – into a helpful assistant that actually answers your questions.
- IFT happens after pre-training, once the model already knows lots of basic facts and logic patterns.
- It works via carefully crafted question-answer pairs to teach conversational skills to the model.
- IFT data is more expensive than pre-training data because humans have to create the examples.
The model doesn’t learn many new facts or ideas during IFT – instead, what it’s doing is teaching the model an interaction pattern. Via IFT, a pre-trained model goes from a very knowledgeable but rambling word generator into something that actually answers your question in a concise and helpful fashion.