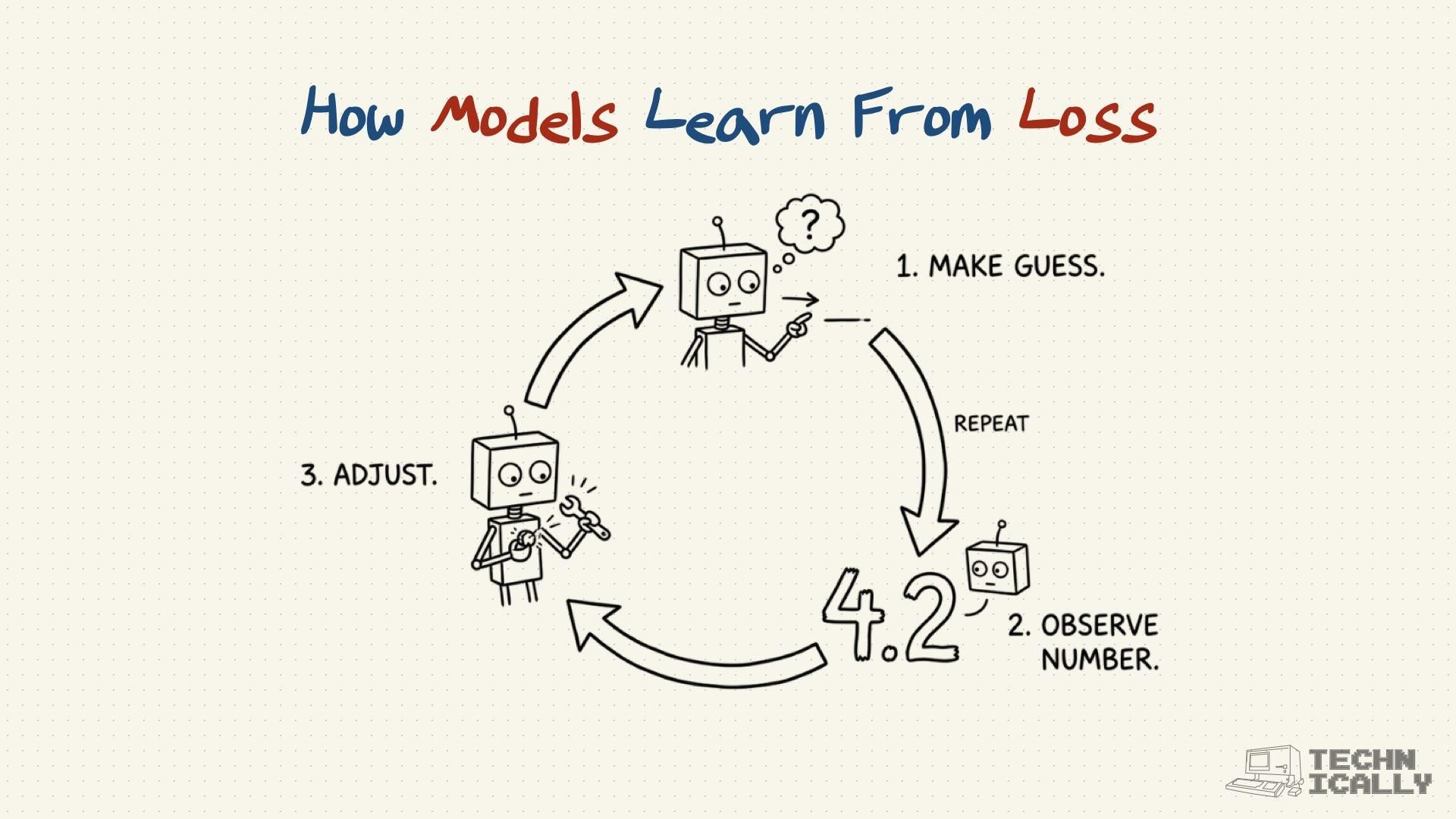
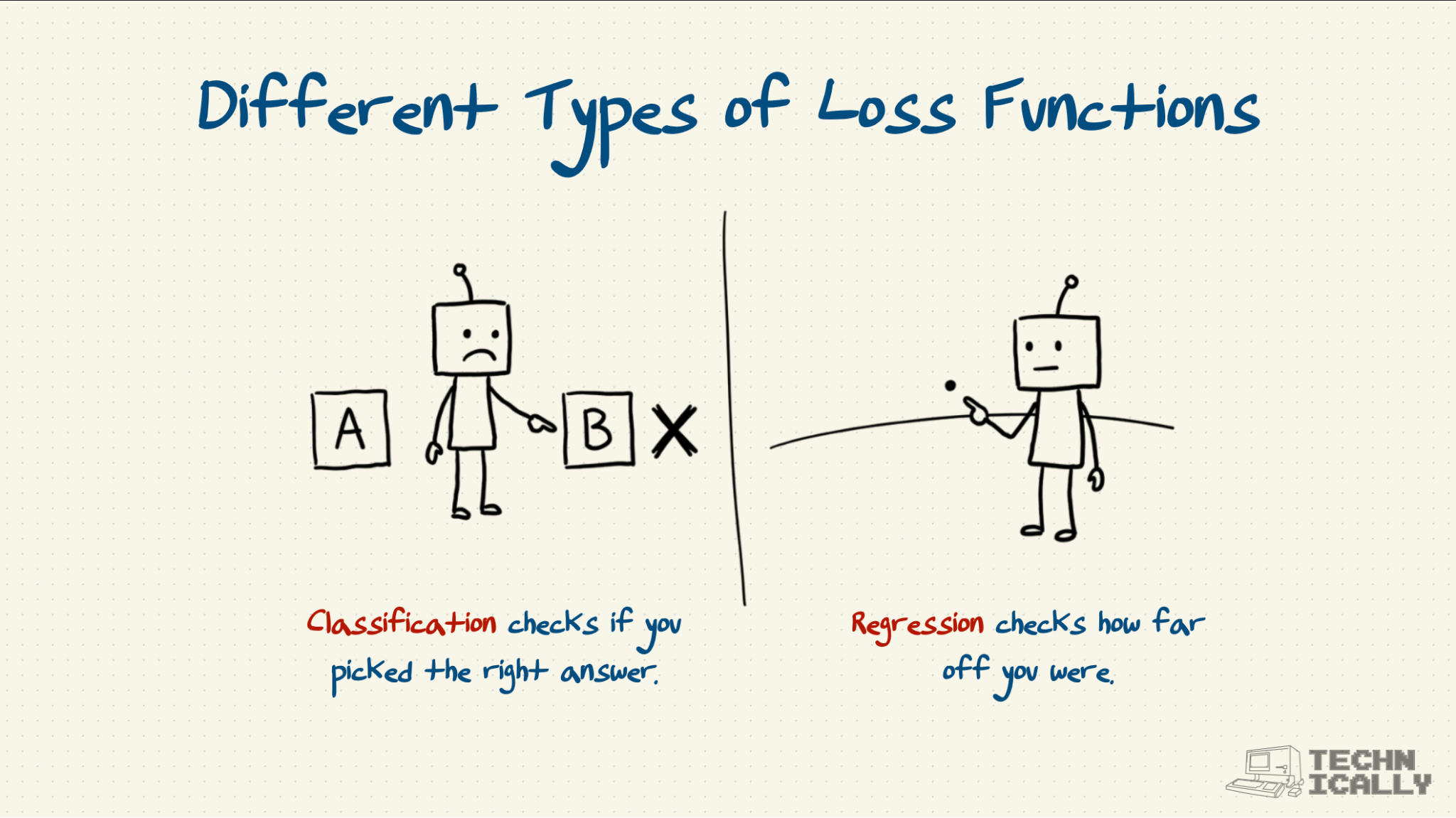Frequently Asked Questions About Loss Function#
Can you change the loss function during training?#
You can, but it's usually not a great idea. Changing the loss function mid-training is like changing the rules of the game while someone's learning to play - it tends to confuse the model rather than help. Most people stick with one loss function for the entire training process.
Do modern AI systems use just one loss function?#
Nope, often they use combinations of multiple loss functions. ChatGPT, for example, uses different loss functions during pre-training (predict the next word), instruction tuning (be helpful), and RLHF (match human preferences). It's like having multiple teachers giving feedback on different aspects of performance.
How do you design a custom loss function?#
Very carefully, and usually by starting with existing loss functions and modifying them. You need to think about what you actually want the model to do, what failure modes you want to avoid, and how to balance different objectives. It often takes several iterations to get right.
Can loss functions be biased?#
Absolutely, and this is a huge concern in AI ethics. If your loss function doesn't account for fairness across different groups, your model will learn to be unfair. For example, a hiring algorithm might optimize for "historical hiring patterns" and perpetuate existing biases.
What's the most common mistake with loss functions?#
Optimizing for the wrong thing because it's easier to measure. For example, optimizing a recommendation system for "clicks" instead of "user satisfaction" often leads to clickbait. The metrics you choose to optimize become your reality, so choose wisely.