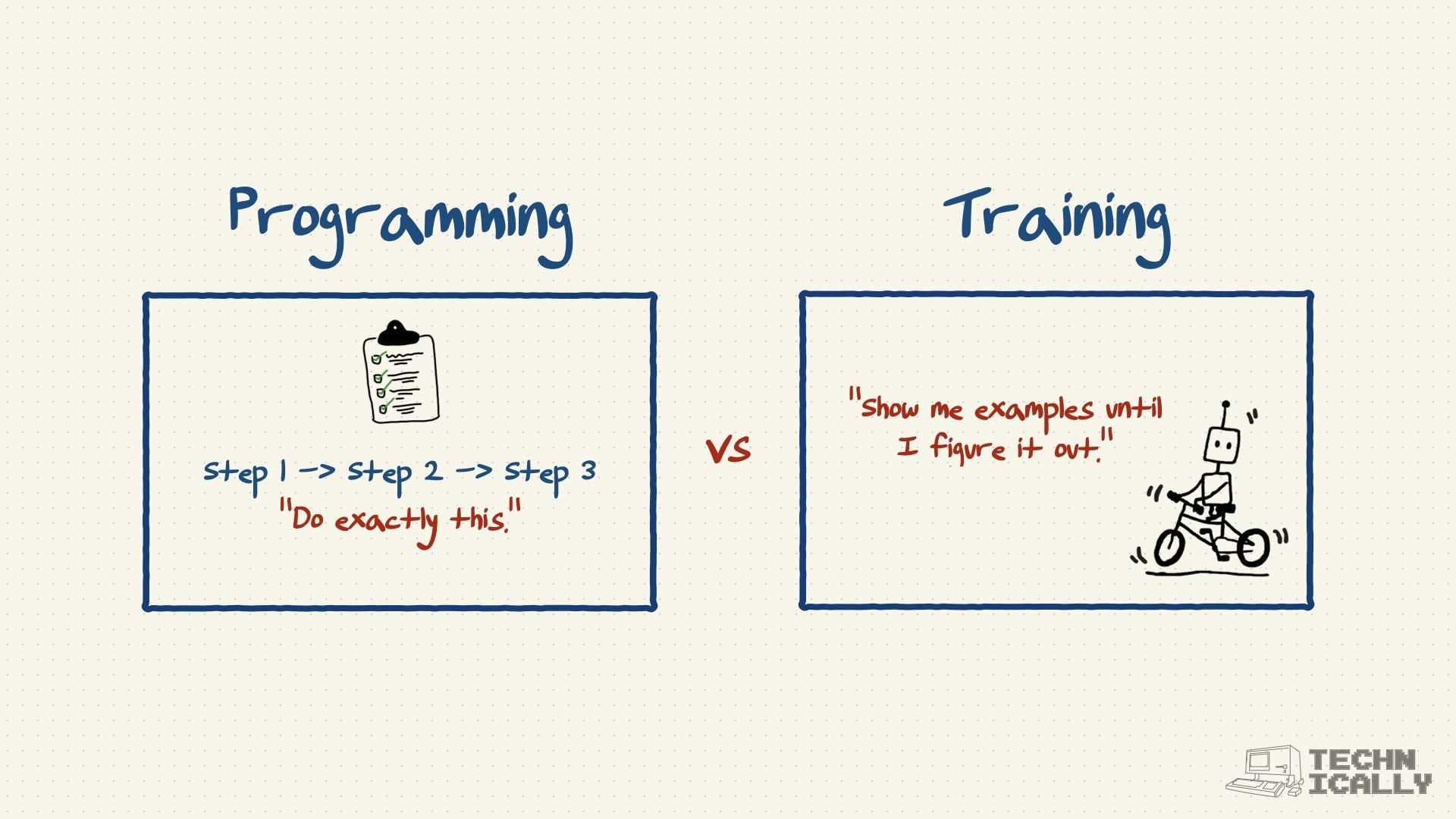
What's the difference between old school ML training and generative AI training?#
The difference mostly comes down to what you are asking the model to do: pass a multiple-choice test or write a creative essay.
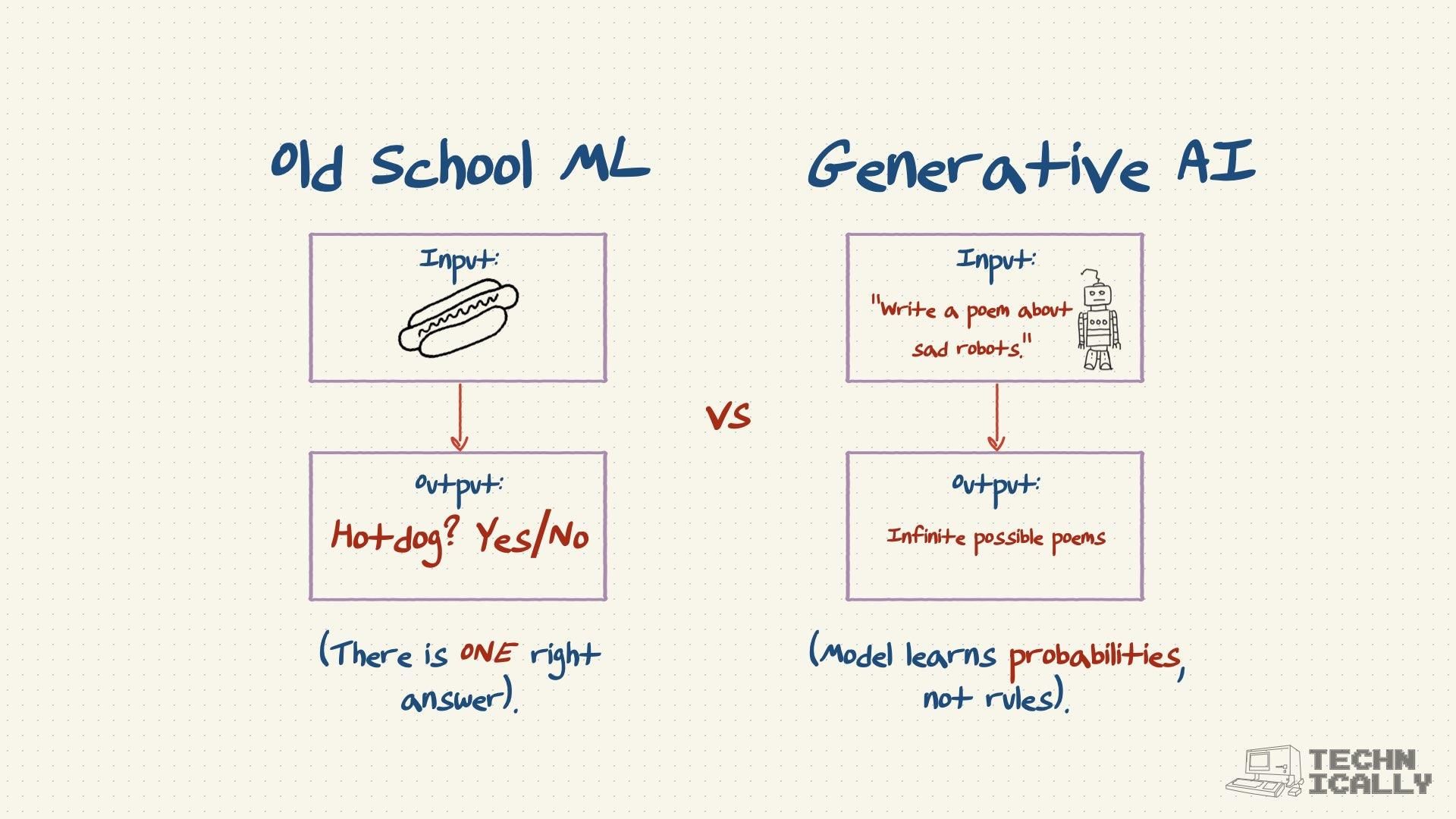
1. Traditional Machine Learning (Old School)
This is straightforward. You train the model on clear inputs and outputs.
- Input: A picture.
- Goal: Is it a hot dog? Yes or No.
There is a clear right answer. The model learns to draw a line between "hot dog" and "not hot dog." Our brains do the same via basic logic; the model is a little different, and is using fancy math to make a statistical decision based on the pixels of the input image.
2. Generative AI (New School)
This is much trickier because there is no single "correct" answer when you want a model to generate text. If you ask ChatGPT to "write a poem about sad robots," there are infinite valid responses. Instead of learning strict rules, the model learns probability distributions. It figures out what words usually follow other words to create a sentence that sounds human.
So obviously, training this kind of model is a very different kind of task. Instead of a nice labeled dataset of inputs and outputs, the model is trained to predict the next word in a sentence over and over again…among other things (more on this later).