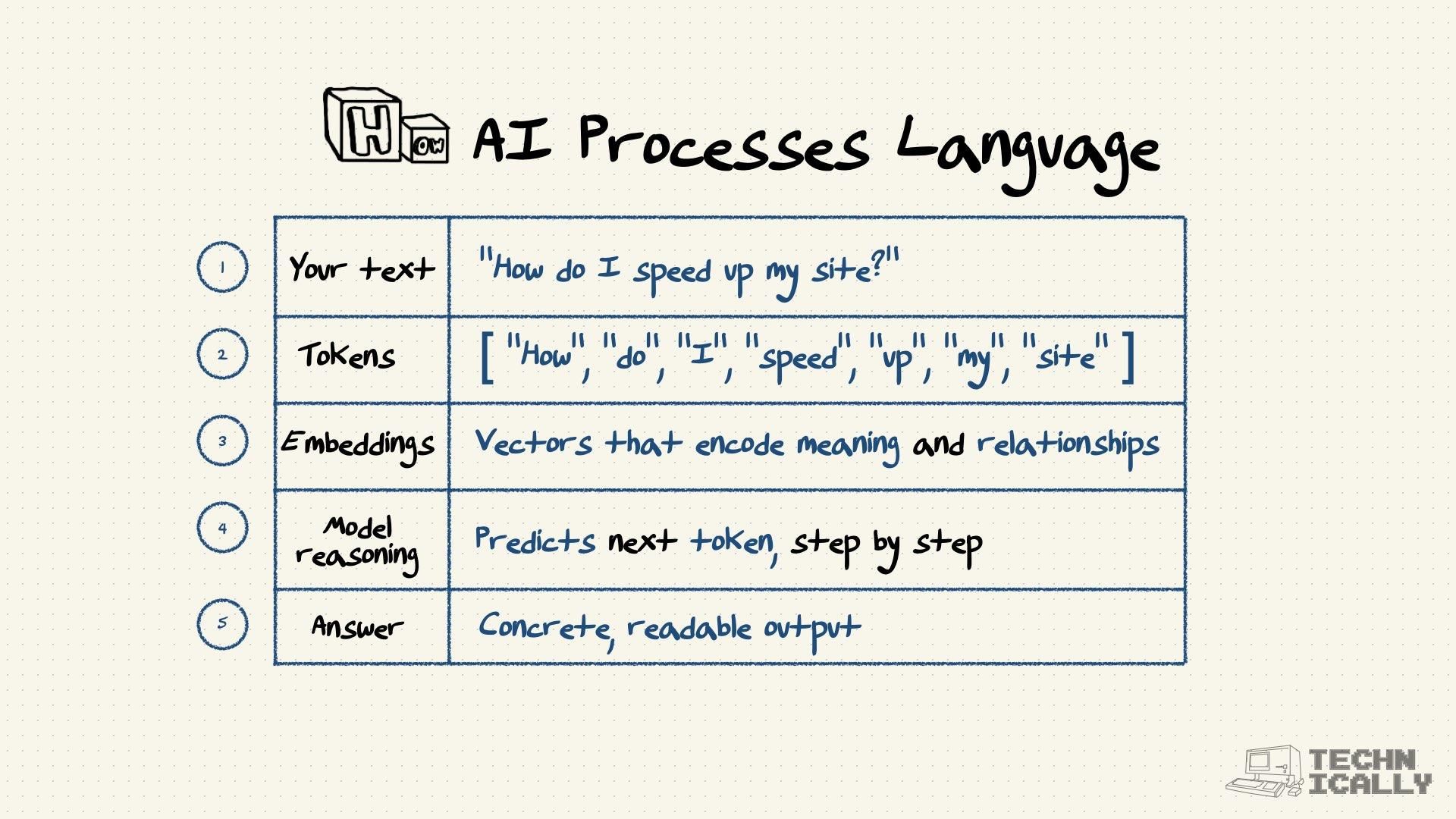
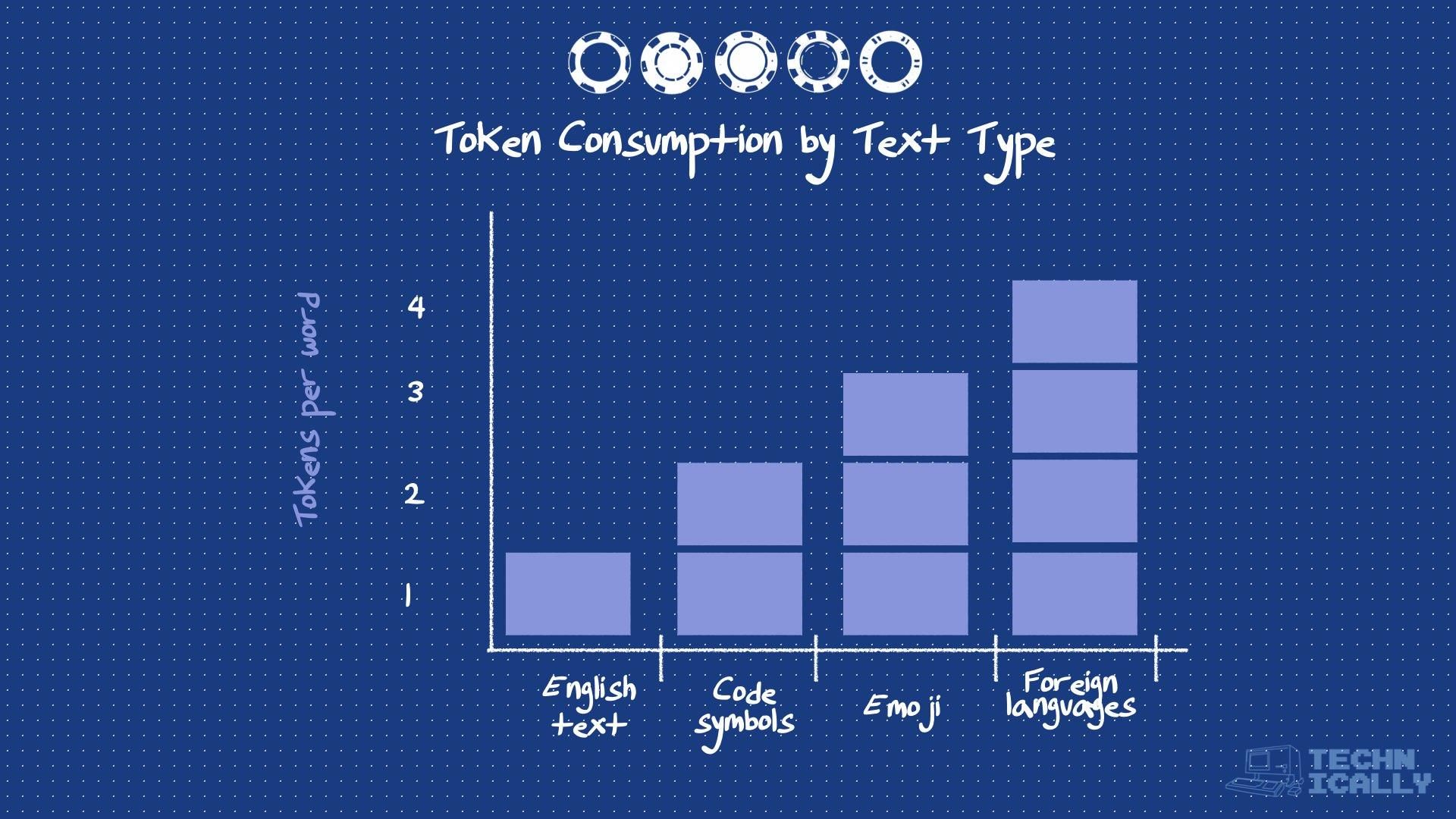
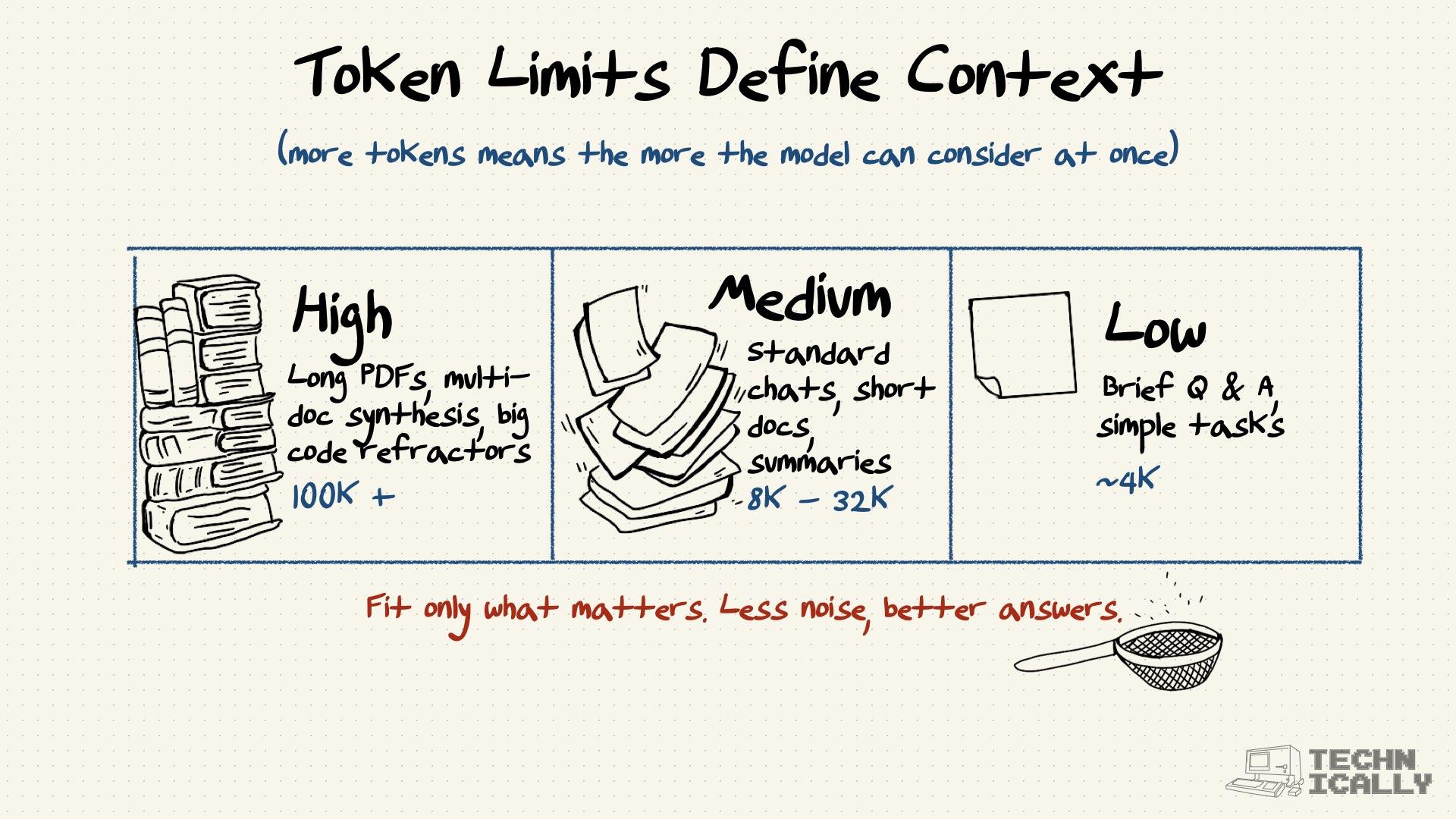
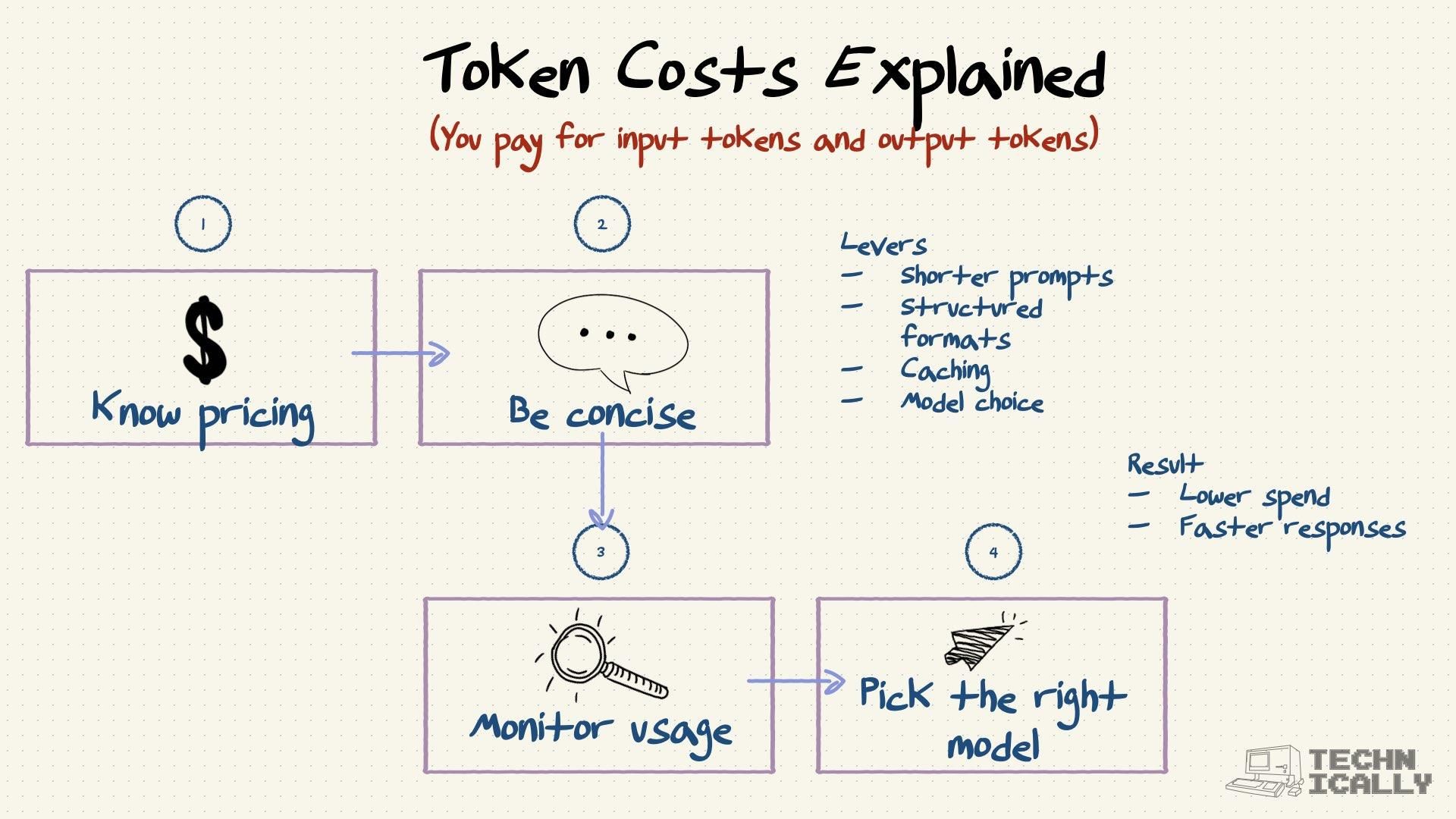
What determines token limits?#
Token limits are determined by the AI model's architecture and the computational resources available:
Model Architecture #
The "context window" is built into the model's design. GPT-3.5 handles about 4,000 tokens, while GPT-4 can handle 8,000-128,000 depending on the version. GPT-5 significantly expands this, offering up to 400,000 tokens via the API, though the limit for ChatGPT users is generally between 32,000 and 128,000 tokens, depending on their subscription tier and the specific model variant used (like the 'Thinking' or 'Fast' mode). Anthropic's Claude models (like Opus and Sonnet), on the other hand, typically offer a 200,000-token context window, with API and Enterprise versions extending to 500,000 or even 1 million tokens.
Memory Constraints #
Processing longer token sequences requires more memory and computational power, which increases costs exponentially.
Quality Trade-offs #
Models generally perform better with shorter contexts where they can focus on the most relevant information.
Recent Improvements #
Newer models are dramatically increasing context windows—from 4,000 tokens to over 1 million in some cases—making this less of a practical limitation.