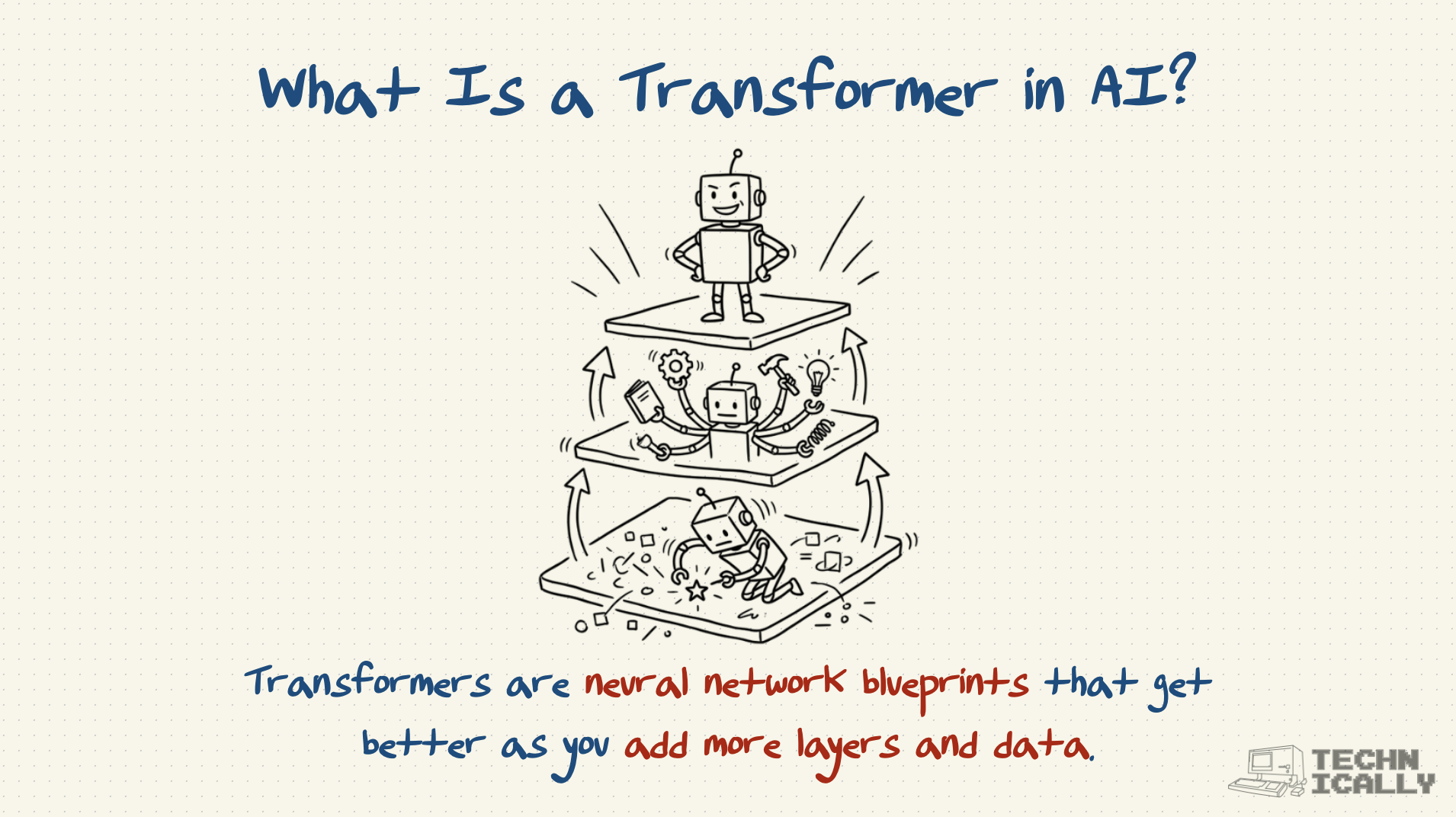
Transformers are the neural network architecture that powers modern AI like ChatGPT, revolutionizing how models process language and other sequential data.
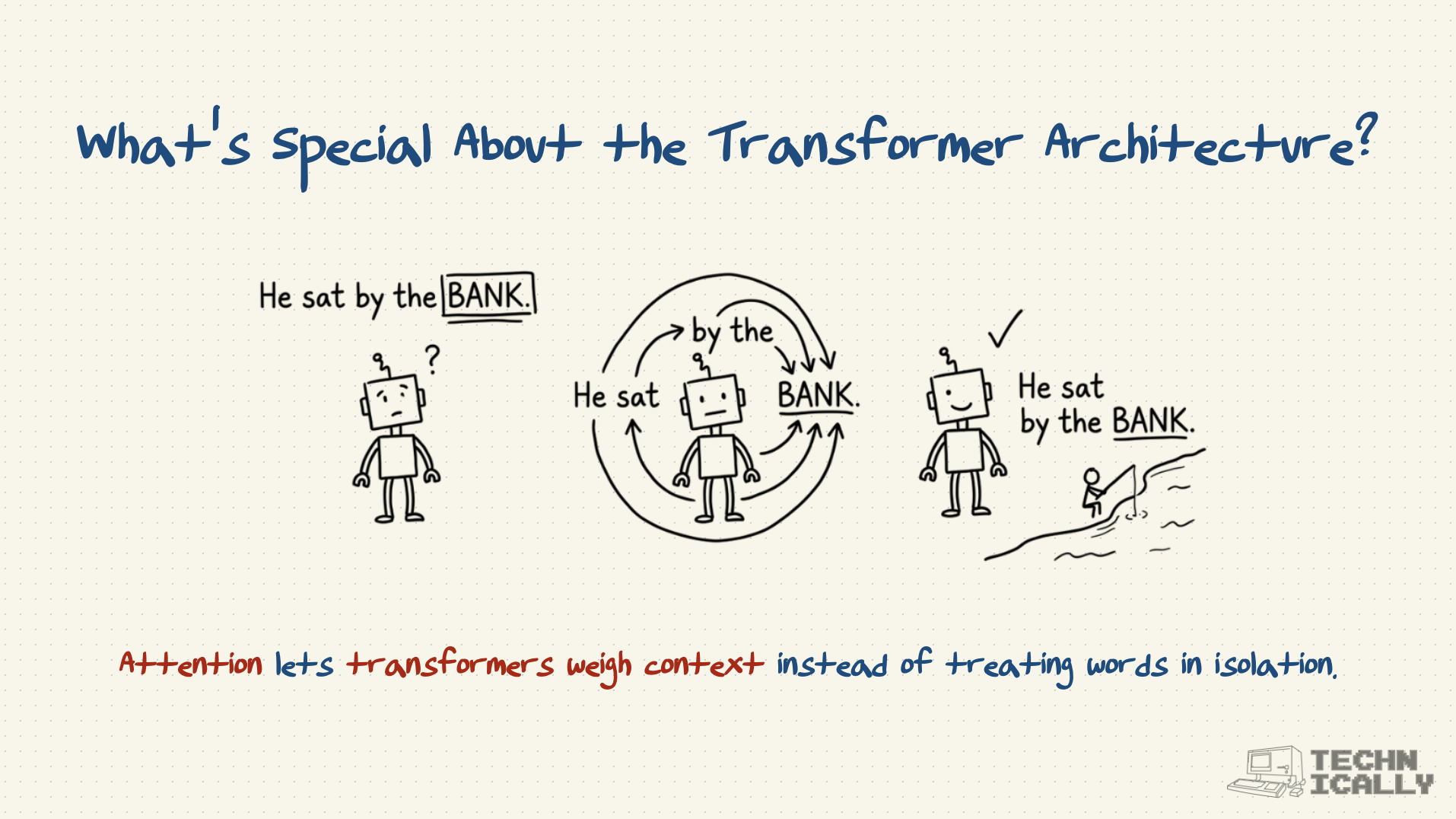
- Breakthrough "attention mechanism" lets models focus on relevant parts of input
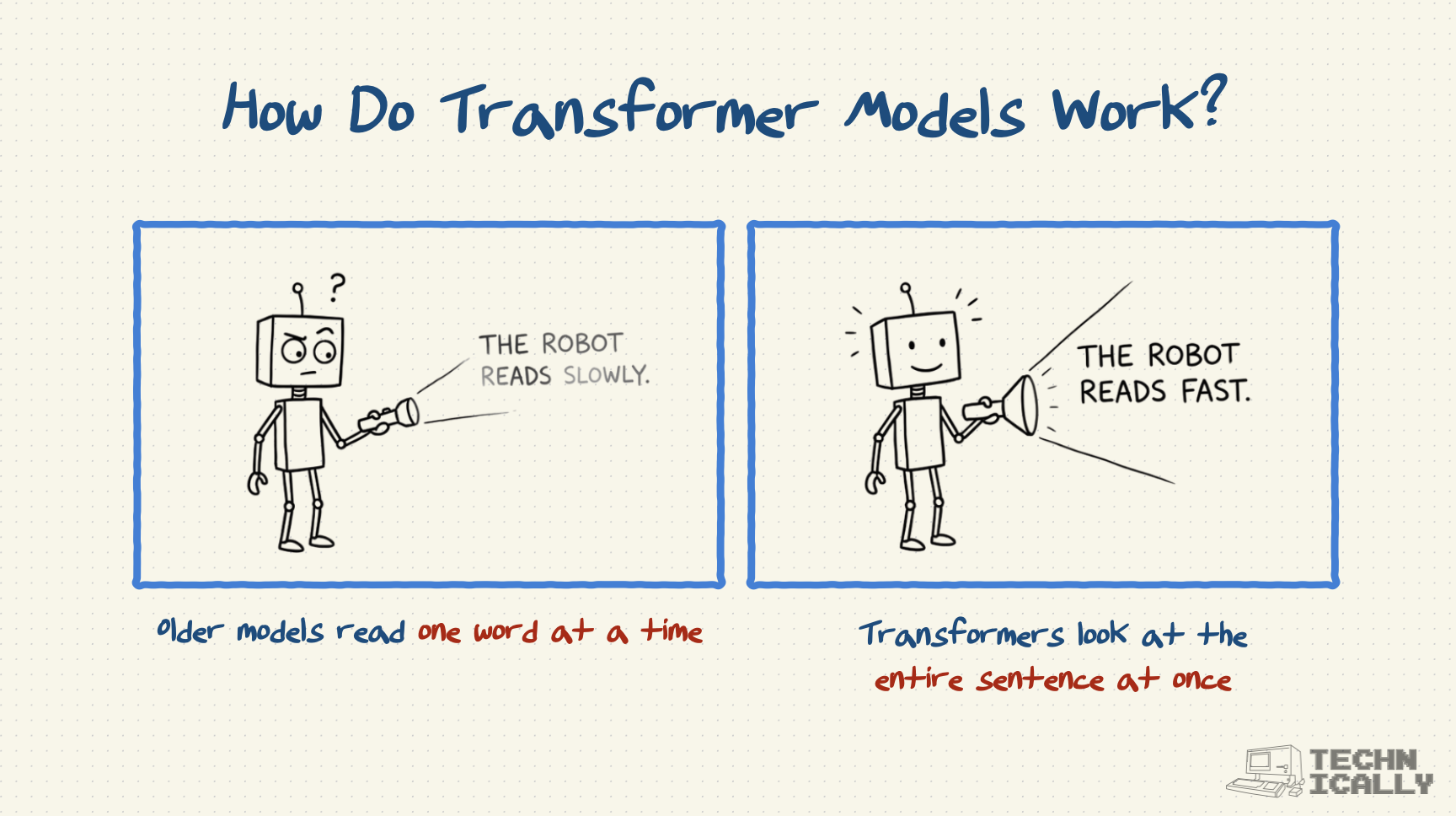
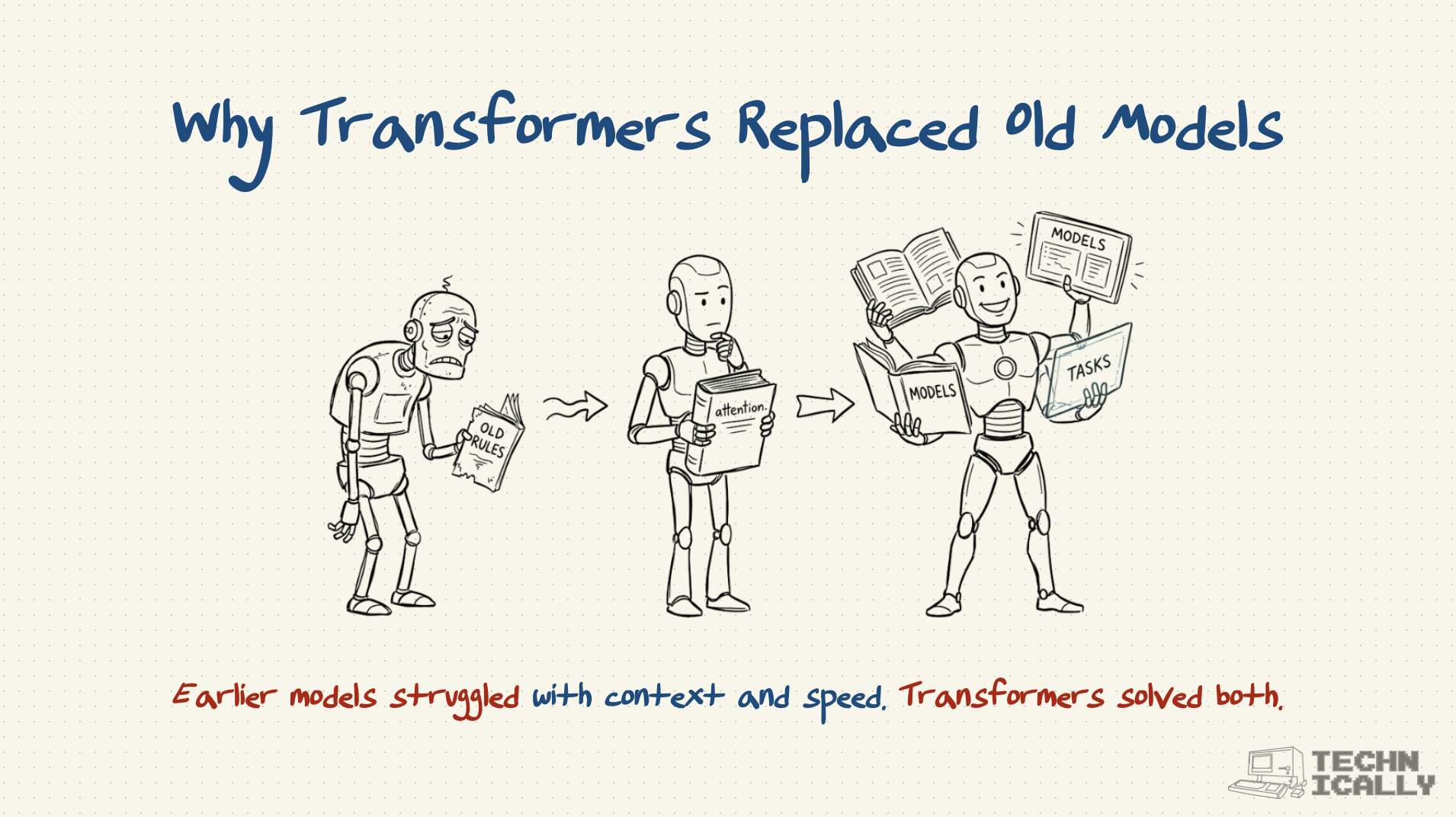
- Replaced older architectures that processed information sequentially
- Powers all major language models: GPT, Claude, Gemini, and others
- Think spotlight that can illuminate multiple things at once versus flashlight pointing at one thing
Transformers turned AI from reading word-by-word to understanding entire contexts instantly.