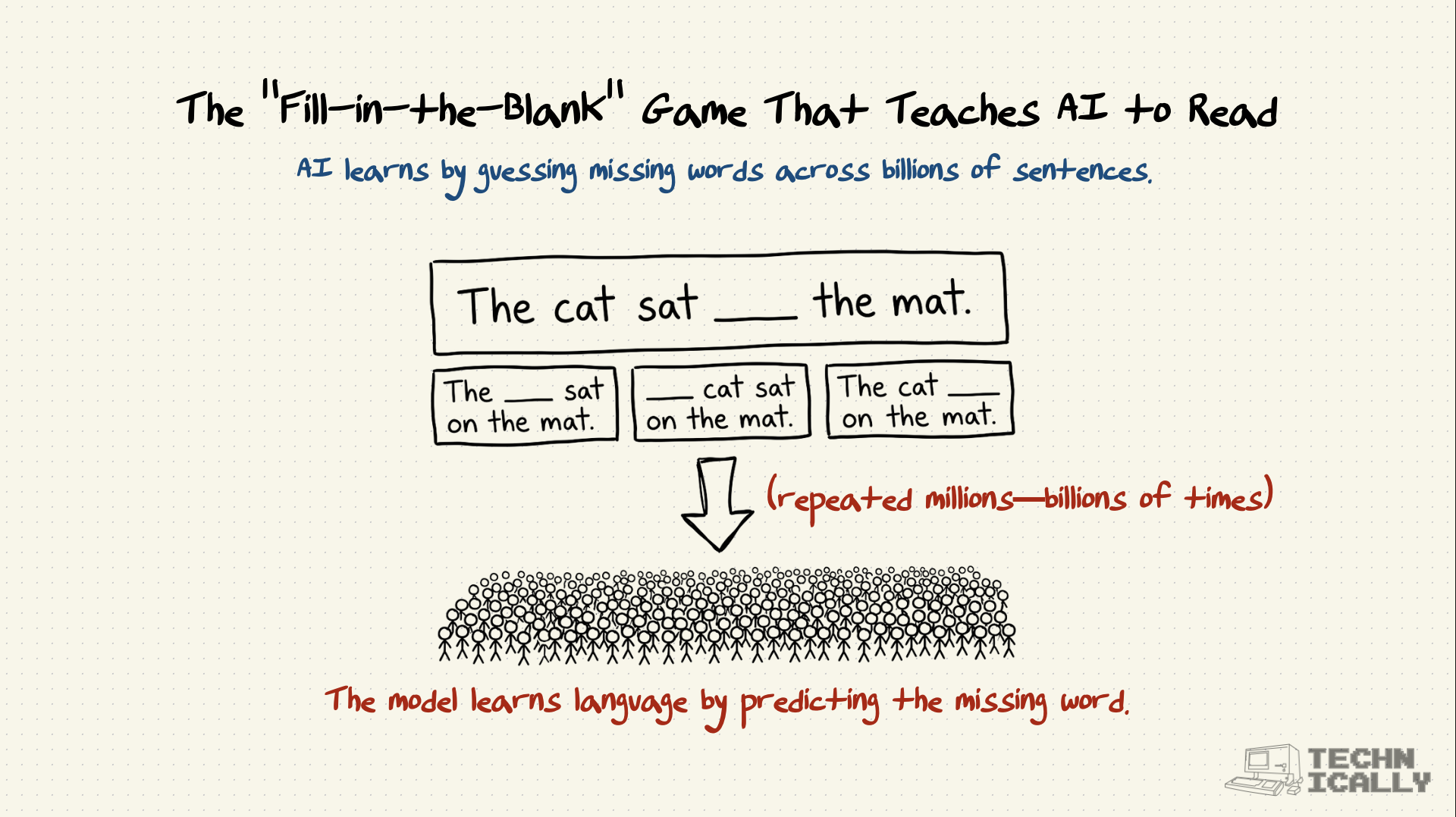
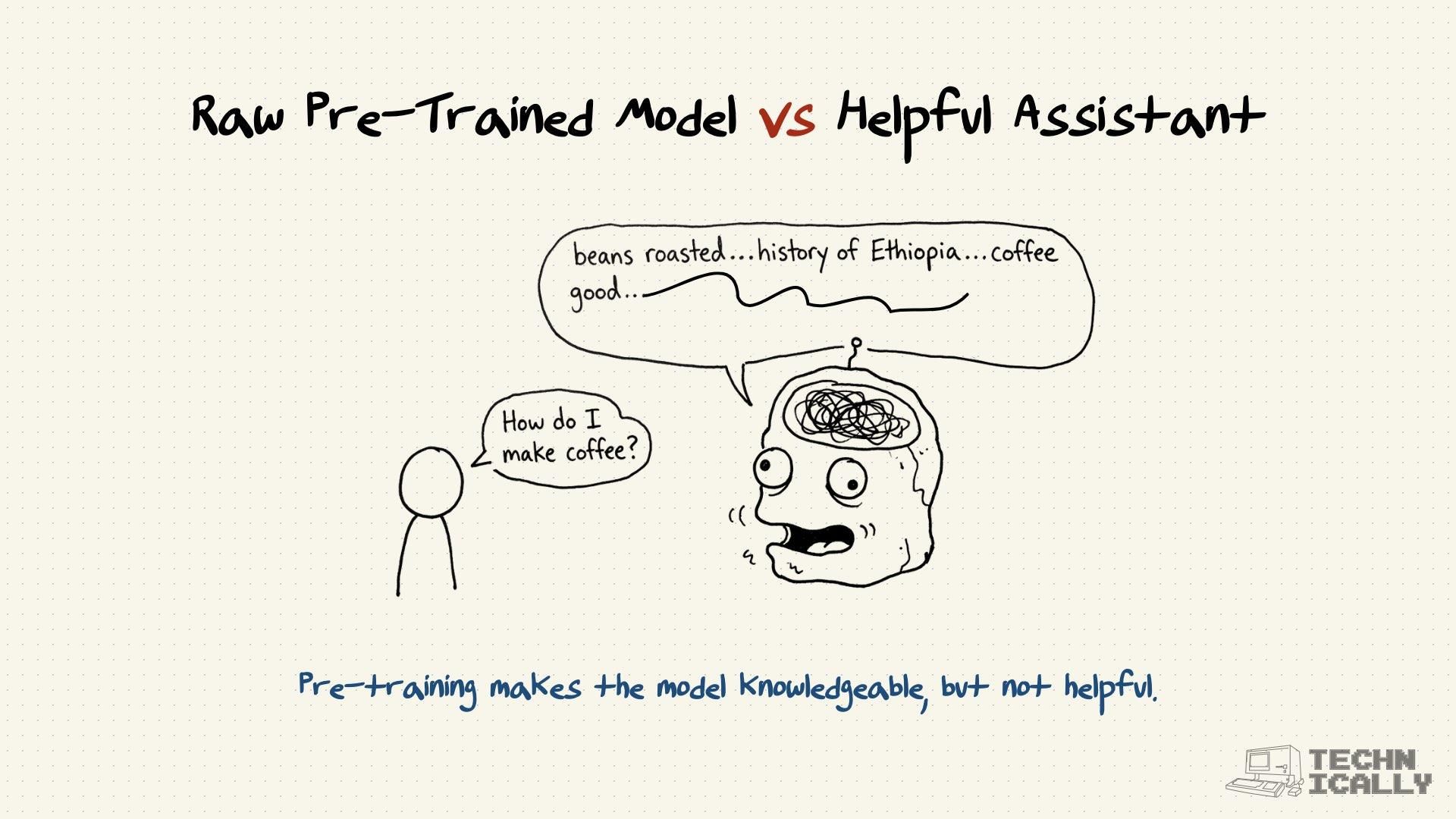
Frequently Asked Questions About Pre-Training#
Can you skip pre-training?#
No. If you skip pre-training, your model is literally a random number generator. It needs that foundational understanding of language to function. It’s like trying to teach someone to write poetry before they know the alphabet.
Do all AI models need pre-training?#
Pretty much any model dealing with complex stuff like language or images does. If you're just making a simple Excel formula to predict next month's sales, you don't need it. But for "AI" as we know it today? Yes.
Can you pre-train on private data?#
You can, but it's rare. Pre-training requires massive amounts of data (trillions of words). Most companies don't have enough internal documents to fill a disk, let alone train a model from scratch. Usually, companies take a model that has already been pre-trained on the internet and then fine-tune it on their private data.
What happens if pre-training data is biased?#
The model becomes biased. Period. Since the internet contains racism, sexism, and other -isms, the model absorbs those patterns during pre-training. Companies spend a lot of time in the later stages (Fine-tuning/RLHF) trying to "un-teach" these bad habits, but it's an ongoing battle.
How often do companies redo pre-training?#
Almost never. It costs way too much money (we're talking tens of millions for the big models). Companies usually pre-train a base model once (like GPT-5) and then spend the next several months just tweaking and fine-tuning it.