Other FAQs about inference#
There are several tricks you can use at inference time: better prompting techniques, combining multiple models (like getting a second opinion), using RAG to pull in fresh information, and adding filters to clean up outputs. But if you want fundamental improvements to what the model can actually do, you're usually looking at retraining or fine-tuning territory.
What's the difference between inference and prediction?#
People use these terms pretty interchangeably, but "prediction" usually means forecasting future stuff, while "inference" covers the whole range of AI tasks—classification, text generation, analysis, whatever. All predictions are inferences, but not all inferences are predictions.
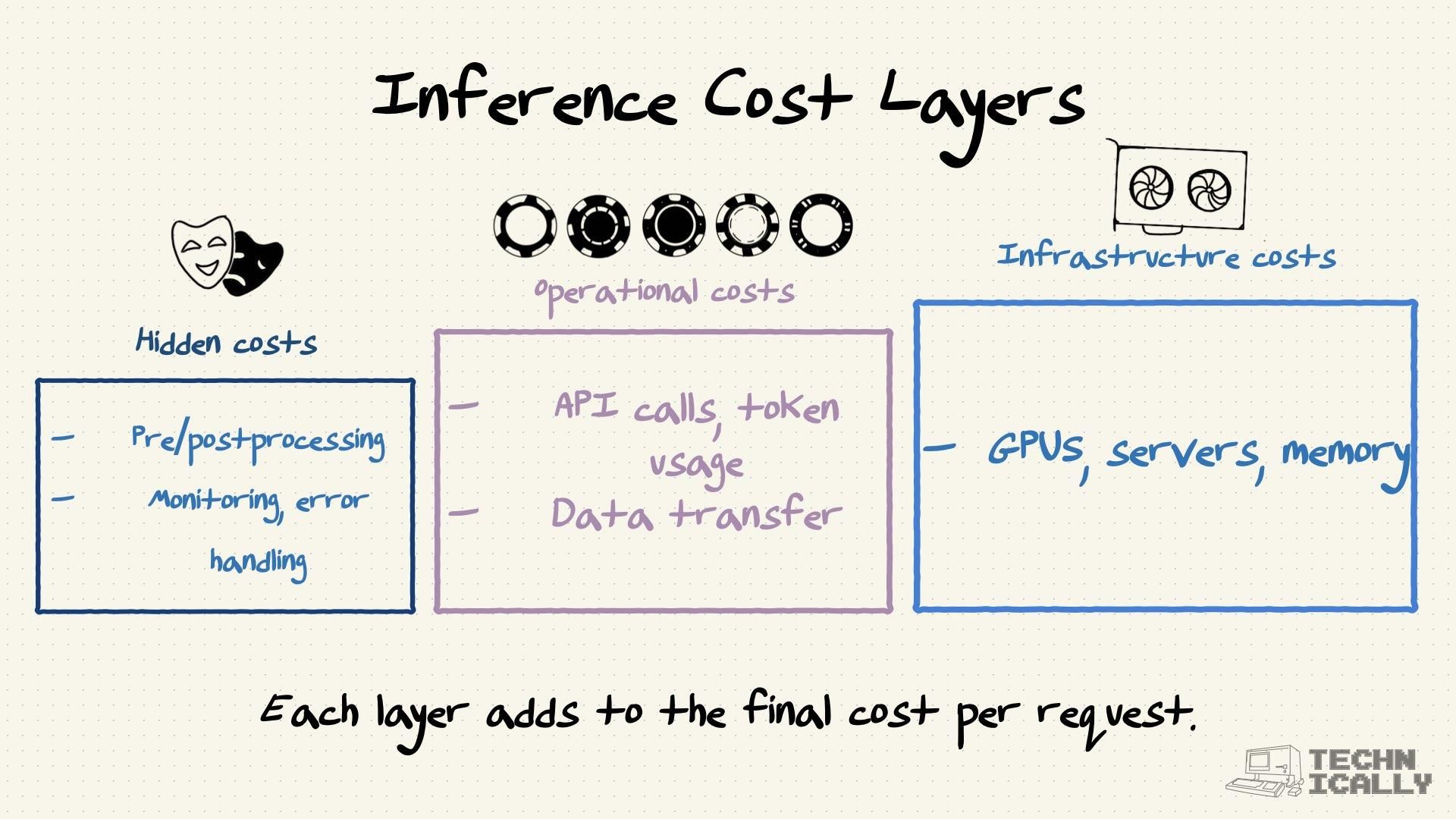
Four main things to watch: how fast the model responds (latency), how many requests it can handle at once (throughput), how good the outputs are (quality), and how much each request costs. Which one matters most depends on what you're building—real-time apps care about speed, batch processing jobs care about throughput and cost.
Can inference work without internet?#
Absolutely. Edge inference runs locally on your device with no internet required. Common in mobile apps and privacy-sensitive stuff where you don't want data leaving the device. The trade-off is you're usually stuck with smaller, less capable models because of hardware limitations—your phone can't run the same models that live on massive server farms.
What happens when inference fails?#
Depends on how you've set things up. Good systems have fallback plans: try a backup model, escalate to humans, or gracefully degrade (maybe switch from AI-generated responses to canned ones). For critical applications, you definitely want error handling built in from day one—nobody wants their customer service bot to just crash when things go sideways.
How secure is inference?#
Security has two sides: protecting the model itself (from theft or tampering) and protecting your data (from unauthorized access). This usually means encrypted communications, secure hosting, input validation, and audit logs. For really sensitive stuff, there are even techniques that let you run inference on encrypted data, though that gets pretty complex pretty fast.