RLHF is the final training step that turns a knowledgeable but rambling AI into the helpful assistant you know and love.
- RLHF uses human feedback to teach AI what "good" and "bad" responses look like
- Humans rate AI outputs, and the model learns from those ratings
- It's why ChatGPT feels more helpful and less robotic than earlier AI models
- Think of it as the "manners training" for AI — teaching it how to be useful, not just correct
RLHF is the secret sauce that makes modern AI feel surprisingly human-like in its responses.
What is RLHF?#
RLHF stands for Reinforcement Learning from Human Feedback, and it's essentially the difference between an AI that knows a lot of facts and an AI that knows how to be helpful.
Before RLHF, you might ask an AI a simple question and get a technically correct but completely unhelpful 500-word academic treatise. After RLHF, you get a concise, actually useful answer.
How does RLHF work?#
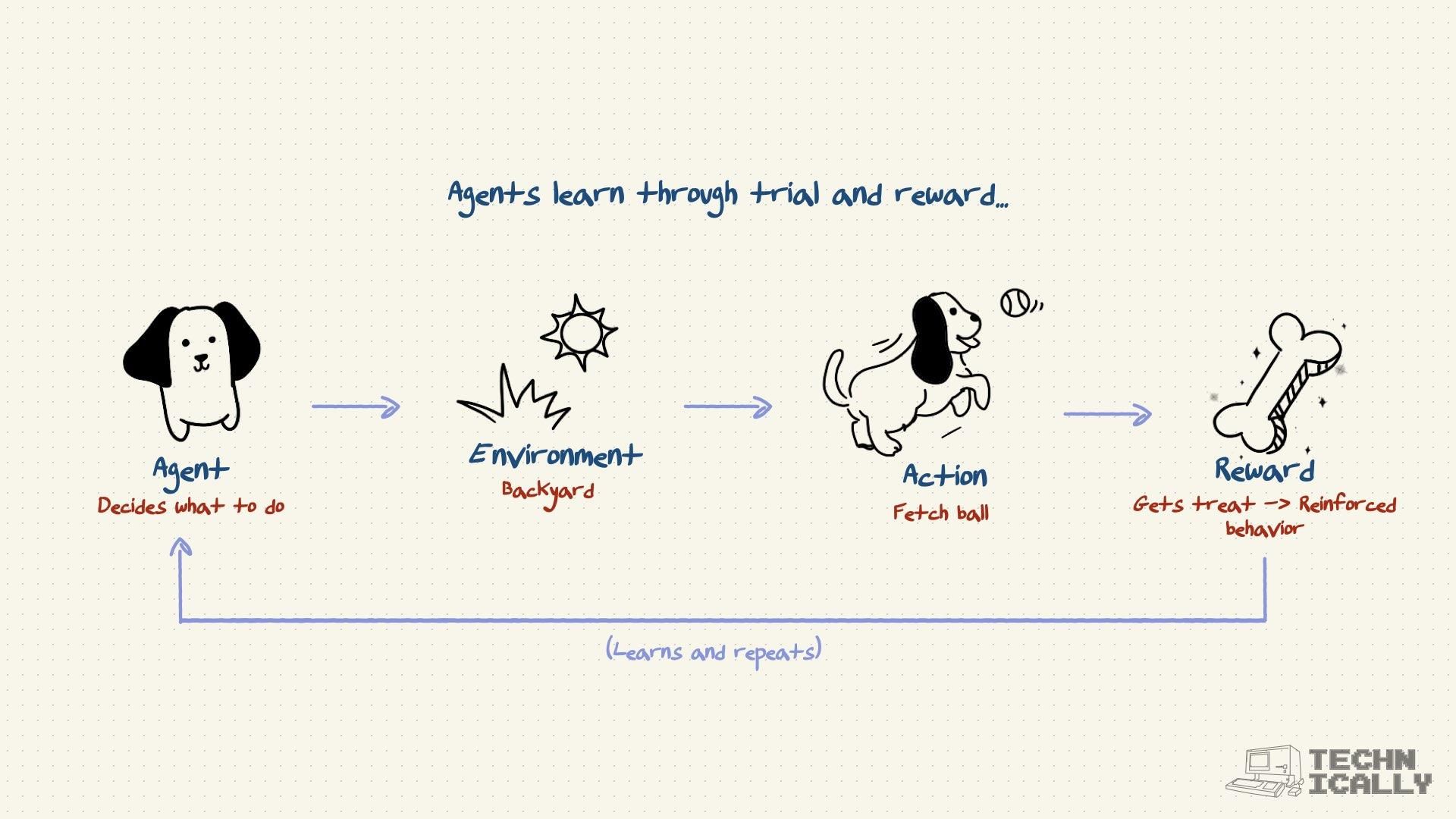
Though a simple idea, getting RLHF done in practice, slightly more complex. How do you integrate human feedback into the brain of the model? Reinforcement Learning, the RL in the acronym, is an entire discipline of Machine Learning that has existed for decades. It's most popular in domains like gaming, but works here too.
Here's the process in practice:
Step 1: Generate Multiple Responses #
The AI model creates several different answers to the same question.
Step 2: Human Ranking #
Real humans look at these responses and rank them from best to worst. They consider factors like helpfulness, accuracy, tone, and whether the response actually answers the question.
Step 3: Learn from Feedback #
The model learns to prefer responses that humans rated highly and avoid patterns that got low ratings.
Step 4: Repeat #
This process happens thousands of times with different questions and scenarios until the model develops reliable intuition about what makes a good response.
Why is RLHF important for GenAI models?#
Without RLHF, ChatGPT would be like a brilliant professor who can't stop lecturing. It would know everything but be terrible at conversation. RLHF teaches the model crucial skills like:
- Brevity: Don't write a novel when a paragraph will do
- Relevance: Actually answer the question being asked
- Tone: Match the formality level of the conversation
- Safety: Avoid harmful or inappropriate content
- Helpfulness: Focus on what the human actually needs
This is why ChatGPT feels like you're talking to a knowledgeable assistant rather than reading a Wikipedia article.
What's the difference between RLHF and other training methods?#
Traditional AI training is like teaching someone facts from textbooks. RLHF is like teaching them social skills and common sense.
- Pre-training: "Here's all the information on the internet. Learn everything." Fine-tuning: "Here are examples of good question-answer pairs."
- RLHF: "Here's how to actually be helpful in conversation."
It's the difference between knowing that Paris is the capital of France and knowing when someone asks about Paris whether they want tourist recommendations, historical facts, or directions to the airport.
How do humans provide feedback to AI models?#
The process is more systematic than you might think. Companies like OpenAI hire human reviewers who:
- Read AI responses to various prompts
- Rate quality on multiple dimensions (helpfulness, accuracy, safety)
- Provide specific feedback about what could be improved
- Rank multiple responses to the same question
- Flag problematic content that the model should avoid
These reviewers often have detailed guidelines about what constitutes a good response, and their feedback gets aggregated to train the model.
What is reinforcement learning?#
Reinforcement learning is like training a dog, but with math. The basic idea is simple:
- Do something good → Get a reward
- Do something bad → Get penalized
- Learn over time what actions lead to rewards
In RLHF, the "rewards" are high human ratings, and the "penalties" are low ratings. The AI learns to generate responses that maximize its expected reward (human approval).
This is different from traditional machine learning, where you show the model examples of right answers. In reinforcement learning, the model has to figure out what "right" means by trying different approaches and seeing what gets rewarded.
Other FAQs about RLHF#
How many humans are involved in RLHF?#
It varies by company, but we're talking about hundreds or thousands of human reviewers for major models like ChatGPT. These aren't just random people off the street — they're often trained reviewers who understand the guidelines and can provide consistent feedback.
Is RLHF expensive?#
Very. Paying humans to carefully read and rate AI responses is time-consuming and costly. This is one reason why RLHF is typically the final step in training — you want to get the model as good as possible through cheaper methods first.
Can RLHF go wrong?#
Absolutely. If the human feedback is biased or inconsistent, the model learns those biases. If reviewers prefer responses that sound confident even when wrong, the model might become overconfident. This is why companies spend so much effort on training their human reviewers and establishing clear guidelines.
Do all AI models use RLHF?#
Not all, but most consumer-facing AI products do some form of it. Any AI that's designed to interact with humans conversationally has probably been through RLHF or similar human feedback processes. It's become the industry standard for making AI helpful rather than just knowledgeable.
What happens after RLHF?#
RLHF isn't a one-time thing. Companies continuously collect feedback from real users and periodically retrain their models with new human feedback data. It's an ongoing process of refinement to keep the AI aligned with human preferences and expectations.